The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts.
Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits—changes that target specific attributes of an image while leaving
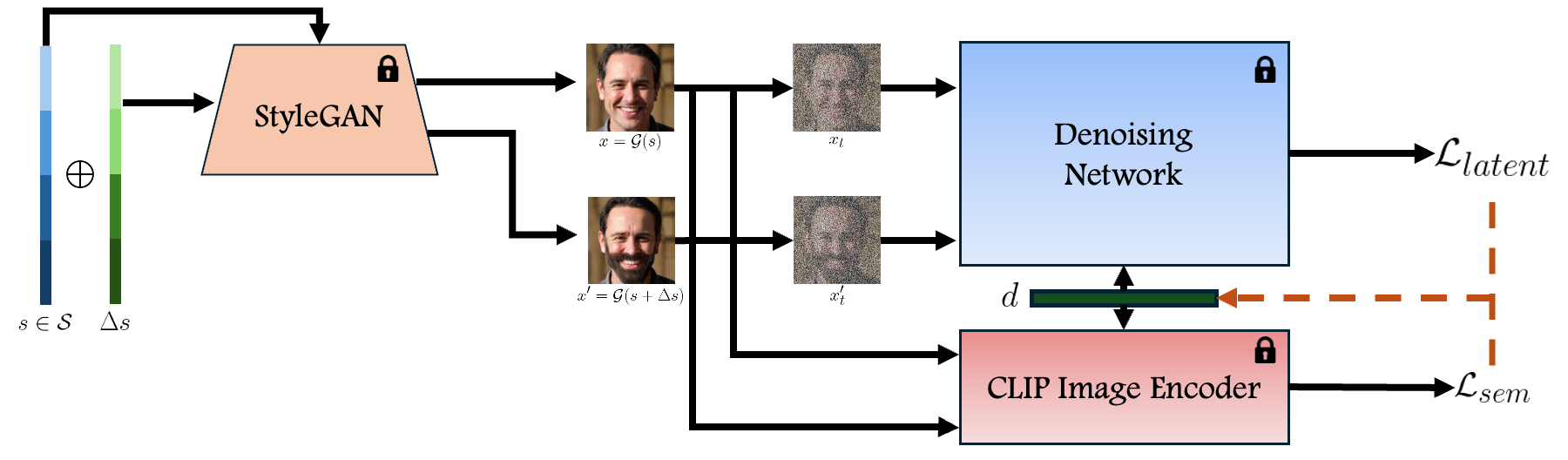
irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC,
a novel framework that takes existing directions from pre-trained GAN models—representative of specific, controllable attributes—and transfers these directions into diffusion-based models. This novel approach not only
maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.